🚀 Getting Started#
📦 Installation#
Install published package:
pip install mllm-shap
For local monorepo development, prefer:
make install
💬 Quick Text Example#
This minimal example runs SHAP attribution on single text prompt.
import pandas as pd
import torch
from mllm_shap.connectors import LiquidAudio, ModelConfig
from mllm_shap.connectors.enums import ModelHistoryTrackingMode, Role, SystemRolesSetup
from mllm_shap.connectors.filters import ExcludePunctuationTokensFilter
from mllm_shap.shap import Explainer, McShapExplainer
from mllm_shap.shap.embeddings import MeanReducer
from mllm_shap.shap.enums import Mode
from mllm_shap.shap.normalizers import PowerShiftNormalizer
from mllm_shap.shap.similarity import CosineSimilarity
from mllm_shap.utils.jupyter import display_shap_colors_df
device = torch.device("mps") if torch.backends.mps.is_available() else torch.device("cpu")
model = LiquidAudio(device=device, history_tracking_mode=ModelHistoryTrackingMode.TEXT)
shap = McShapExplainer(
num_samples=-1,
mode=Mode.CONTEXTUAL,
embedding_reducer=MeanReducer(),
similarity_measure=CosineSimilarity(),
normalizer=PowerShiftNormalizer(power=2.0),
)
explainer = Explainer(model=model, shap_explainer=shap)
chat = model.get_new_chat(
system_roles_setup=SystemRolesSetup.SYSTEM_ASSISTANT,
token_filter=ExcludePunctuationTokensFilter(),
)
chat.new_turn(Role.SYSTEM)
chat.add_text("You are a helpful assistant that answers briefly.")
chat.end_turn()
chat.new_turn(Role.USER)
chat.add_text("Who are you?")
chat.end_turn()
result = explainer(
chat=chat,
verbose=True,
generation_kwargs={"max_new_tokens": 64, "model_config": ModelConfig(text_temperature=0.2)},
progress_bar=True,
)
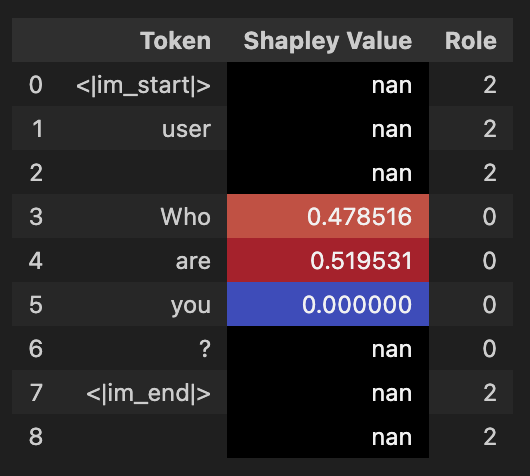
user_entry = result.full_chat.get_conversation()[1][0]
df = pd.DataFrame(
list(zip(user_entry.content, user_entry.shap_values, user_entry.roles)),
columns=["Token", "Shapley Value", "Role"],
)
display_shap_colors_df(df)
🖼️ Output Example#
🎧 Audio Workflows#
For complete audio input/output walkthroughs, use notebooks from repository:
➡️ Next Steps#
API module reference: 🧩 API Reference
Experiment runner docs: 🧪 Experiments Runner
Additional implementation notes: 📝 Additional Notes